










- シンクタンクならニッセイ基礎研究所 >
- 保険 >
- 保険計理 >
- 「空振り」と「見逃し」どちらが問題?-機械学習の評価尺度には人間の感覚が生かされている
「空振り」と「見逃し」どちらが問題?-機械学習の評価尺度には人間の感覚が生かされている

保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員 篠原 拓也


文字サイズ
- 小
- 中
- 大
例えば、誰しもが日々行っているであろうこととして、パソコンやスマートフォンに送られてくるメールのうち迷惑メールを仕分けて削除等の処理を判断する。気象情報では、気象庁の予報官が、台風などの低気圧の接近に伴って、線状降水帯による大雨の呼びかけを行うか判断する。医療の現場では、医師が、コロナウイルスやHIVのような感染症について、検査にもとづく診断を行う、といったことが挙げられる。
これらの判断は、基準を明確化すれば機械的に行うことが可能だ。つまり、AIによる判断が可能となる。ただし、人間が行うにせよ、AIが行うにせよ、判断が100%正しいとは限らない。
線状降水帯の発生予報で言えば、発生する予報を出したのに実際は発生しなかった「空振り」と、発生する予報を出さなかったのに実際は発生した「見逃し」の、2種類の誤りが起こり得る。
今回は、こうした判断の誤りについて、AIの機械学習を含めて考えてみたい。
◇ 迷惑メールの判断は慎重に行うべき
例として、迷惑メールの判断と処理について考えてみる。「迷惑メールだと判断して削除し、実際に迷惑メールだった」。「迷惑メールだと判断して削除したが、実際は迷惑メールではなかった」。「迷惑メールではないと判断して削除しなかったが、実際は迷惑メールだった」。「迷惑メールではないと判断して削除せず、実際に迷惑メールではなかった」の4つの場合があり得る。
これらのそれぞれの場合の発生数をまとめたものは、混同行列と呼ばれる。100個のメールについて、混同行列を作ると、次表のようなものとなる。

残りの15個のメールについては、「迷惑メールだと判断して削除したが、実際は迷惑メールではなかった」誤りが7個。「迷惑メールではないと判断して削除しなかったが、実際は迷惑メールだった」誤りが8個あった。
どちらの誤りが問題だろうか。迷惑メールは確かに“迷惑”だが、それを放置したからといって直ちにパソコンやスマートフォンの使用に支障が出る訳ではない。つまり、後者のケースはそれほど深刻な問題ではないと言える。
一方、前者のケースでは、迷惑メールではないのに誤って削除してしまったことになる。もし、そのように削除したメールのなかに重要なものが含まれていたら、もしかすると取り返しのつかない事態に陥ってしまうかもしれない。つまり、前者のケースは重大な問題と考えられる。
上表の迷惑メールの判断の混同行列では、前者の7個の誤りを減らすために、迷惑メールの判断は慎重に行うべき、ということになるだろう。
◇ 感染症の診断は積極的に行うべき
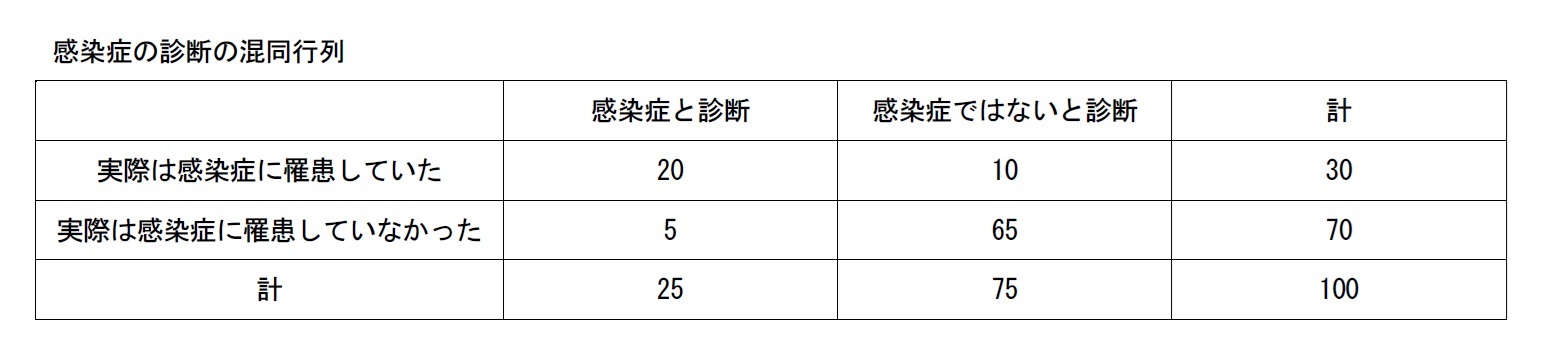
残りの15人の受検者については、「感染症と診断されたが、実際は感染症に罹患していなかった」誤りが5人。「感染症ではないと診断したが、実際は感染症に罹患していた」誤りが10人だった。
統計学や疫学では、前者の5人は「偽陽性」、後者の10人は「偽陰性」と呼ばれる。ちなみに、「感染症と診断され、実際に感染症に罹患していた」20人は「真陽性」。「感染症ではないと診断され、実際に感染症に罹患していなかった」65人は「真陰性」と呼ばれる。
それでは、感染症の診断の場合は、「偽陽性」と「偽陰性」のどちらの誤りが問題だろうか。偽陽性の受検者は、実際は感染症に罹患していないにもかかわらず、自宅や医療施設などで隔離期間を過ごすことになる。当人にとっては、いい迷惑だろう。また、偽陽性の人が多数入院すれば、医療資源の逼迫につながり、他の病気の診療に影響が出るかもしれない。ただし、感染症の拡大という点では、偽陽性が増えてもそれほど問題は生じないと言える。
一方、偽陰性はどうか。偽陰性の受検者は、実際は感染しているにもかかわらず、自宅や医療施設などで隔離されることがない。もし、コロナウイルス感染症のように感染力が強い場合には、偽陰性の人が社会活動を続けることで感染が拡大してしまう恐れがある。つまり、偽陰性は感染症の拡大の点で問題が大きいと考えられる。
上表の感染症の診断の混同行列では、偽陰性の10人を減らすために、感染症の診断は積極的に行うべき、ということになるだろう。
◇ 偽陽性を重視するときは適合率、偽陰性を重視するときは再現率が用いられる
統計学では、偽陽性を問題にするときには、陽性と判断されたうち実際に陽性だった割合である「適合率」という割合を用いる。先ほどの迷惑メールの判断の例では、40/47=85.1% といった具合だ。
この適合率が高いほど、迷惑メールの判断はうまくいったということになる。
一方、偽陰性を問題にするときには、実際に陽性だったうち陽性と判断された割合である「再現率」という割合を用いる。先ほどの感染症の診断の例では、20/30=66.7% となる。
この再現率が高いほど、感染症の診断は(感染症拡大防止の点で)適切だったということになる。
(2024年08月13日「研究員の眼」)

 各種レポート配信をメールでお知らせ。読み逃しを防ぎます!
各種レポート配信をメールでお知らせ。読み逃しを防ぎます!
保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員
篠原 拓也 (しのはら たくや)
研究・専門分野
保険商品・計理、共済計理人・コンサルティング業務
03-3512-1823
- 【職歴】
1992年 日本生命保険相互会社入社
2014年 ニッセイ基礎研究所へ
【加入団体等】
・日本アクチュアリー会 正会員
篠原 拓也のレポート
| 日付 | タイトル | 執筆者 | 媒体 |
|---|---|---|---|
| 2025/05/27 | 気候指数 2024年データへの更新-日本の気候の極端さは1971年以降の最高水準を大幅に更新 | 篠原 拓也 | 基礎研レポート |
| 2025/05/20 | 「次元の呪い」への対処-モデルの精度を上げるにはどうしたらよいか? | 篠原 拓也 | 研究員の眼 |
| 2025/05/13 | チェス盤を用いた伝心-愛情と計算力があれば心は通じる? | 篠原 拓也 | 研究員の眼 |
| 2025/05/09 | 国民負担率 24年度45.8%の見込み-高齢化を背景に、欧州諸国との差は徐々に縮小 | 篠原 拓也 | 基礎研マンスリー |






新着記事
-
2025年10月21日
選択と責任──消費社会の二重構造(2)-欲望について考える(3) -
2025年10月21日
連立協議から選挙のあり方を思う-選挙と同時に大規模な公的世論調査の実施を -
2025年10月21日
インバウンド消費の動向(2025年7-9月期)-量から質へ、消費構造の転換期 -
2025年10月21日
中国、社会保険料徴収をとりまく課題【アジア・新興国】中国保険市場の最新動向(71) -
2025年10月21日
今週のレポート・コラムまとめ【10/14-10/20発行分】
レポート紹介
-
研究領域
-
経済
-
金融・為替
-
資産運用・資産形成
-
年金
-
社会保障制度
-
保険
-
不動産
-
経営・ビジネス
-
暮らし
-
ジェロントロジー(高齢社会総合研究)
-
医療・介護・健康・ヘルスケア
-
政策提言
-
-
注目テーマ・キーワード
-
統計・指標・重要イベント
-
媒体
- アクセスランキング
お知らせ
-
2025年07月01日
News Release
-
2025年06月06日
News Release
-
2025年04月02日
News Release
【「空振り」と「見逃し」どちらが問題?-機械学習の評価尺度には人間の感覚が生かされている】【シンクタンク】ニッセイ基礎研究所は、保険・年金・社会保障、経済・金融・不動産、暮らし・高齢社会、経営・ビジネスなどの各専門領域の研究員を抱え、様々な情報提供を行っています。
「空振り」と「見逃し」どちらが問題?-機械学習の評価尺度には人間の感覚が生かされているのレポート Topへ- 新型コロナウイルス
- ウィズコロナ・アフターコロナ
- 生成AI・AI
- IoT
- デジタルトランスフォーメーション(DX)
- フィンテック(FinTech)
- キャッシュレス
- デジタル通貨
- デジタルプラットフォーム
- マイナンバー
- MaaS、CASE
- SDGs
- ESG
- 気候変動
- カーボンニュートラル・脱炭素社会
- サステナビリティ
- ウェルビーイング
- 生物多様性
- イデコ(iDeCo)
- 新NISA・NISA
- 日本銀行
- 人手不足・人材不足
- 働き方改革
- 人的資本経営
- 従業員エンゲージメント
- テレワーク・在宅勤務
- ダイバーシティ(多様性)社会
- 外国人雇用・就労
- 労働政策
- 地域包括ケア・地域共生社会
- 認知症
- 金融(ファイナンシャル)ジェロントロジー
- 全世代型社会保障
- 社会保障・税改革
- 医療・介護制度改革
- 健康寿命
- 健康経営
- 格差・貧困
- 世代間格差
- パワーカップル
- 未婚化
- プレコンセプションケア
- 少子高齢化
- 東京一極集中
- インバウンド
- シェアリングエコノミー
- Z世代・α世代
- エンタメ
- オフィスレントインデックス
- 生命保険事業概況
- 米中貿易摩擦
- 米国
- 中国
- 欧州
- アジア・新興国
- 韓国
- ASEAN
- 統計
- 確定拠出年金
- 企業型DC
- 資産所得倍増プラン
- 金融リテラシー
- 住宅リテラシー
- 年金制度改革
- インド
- 経済安全保障
- 供給網(サプライ・チェーン)
- 消費者物価指数(CPI)│日本
- 雇用統計│日本
- 鉱工業生産指数│日本
- 貿易統計│日本
- 法人企業統計│日本
- QE速報・予測
- 日銀金融政策決定会合
- 日銀短観│日本
- 資金循環統計│日本
- 景気ウォッチャー調査│日本
- 地域経済報告(さくらレポート)
- マネタリーベース│日本
- GDP等│米国
- FOMC(連邦公開市場委員会)│米国
- 住宅販売・着工│米国
- 雇用統計│米国
- 米個人所得・支出|米国
- ECB政策理事会│欧州
- ユーロ圏消費者物価指数
- ユーロ圏GDP
- ユーロ圏失業率
- 英国雇用関連統計
- 英国金融政策
- 英国GDP
- 将来人口推計
- 人口動態統計
- 宿泊旅行統計
- 中国GDP
- インドGDP
- タイGDP
- マレーシアGDP
- フィリピンGDP
- インドネシアGDP
- ベトナムGDP
- ロシアGDP
- ブラジルGDP
- IMF世界経済見通し
- 企業物価指数
- インド消費者物価
Copyright © NLI Research Institute. All rights reserved.