










- シンクタンクならニッセイ基礎研究所 >
- 保険 >
- 保険会社経営 >
- 大規模言語モデルの裏付け理論-大きいモデルほど高性能!?
大規模言語モデルの裏付け理論-大きいモデルほど高性能!?

保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員 篠原 拓也
このレポートの関連カテゴリ


文字サイズ
- 小
- 中
- 大
このブームは日本では、2000年代に始まっている。ビッグデータと呼ばれる大量のデータを用いることでAI自身が知識を獲得する機械学習が実用化された。さらに、知識などの対象を認識する際に注目すべき特徴を定量的に表すことをAIが自ら行って、知識を習得していくディープラーニング(深層学習)が始まった。
そして、2020年代に入り、大規模言語モデル(LLM)が登場した。これは、ディープラーニングの技術をもとに作られた言語モデルで、人間同士が会話をしたりチャットのやり取りをしたりするのに近いような、流暢な言語処理ができることが特徴となっている。そのためには、相手から発せられた言葉(データ)を解釈して、それに応じて話のテーマの予測を行い、適切に応答することが必要となる。OpenAI社により2022年に導入されたChatGPTなどの生成AIの登場につながっている。
このLLMは、2020年にジョンズ・ホプキンス大学とOpenAI社の研究者によって公表された一編の論文(*)にもとづいている。今回は、その論文について少し見ていきたい。
(*) “Scaling Laws for Neural Language Models” Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei (arXiv:2001.08361 [cs.LG], https://doi.org/10.48550/arXiv.2001.08361)
◇ 「計算量」、「データ量」、「モデルの大きさ」が大きいほど、自然言語モデルの誤差は小さくなる
例えば、1992年刊行のベストセラー「ゾウの時間・ネズミの時間」(本川達雄著, 中公新書)によると、「いろいろな哺乳類で体重と時間とを測ってみると、(中略) 時間は体重の1/4乗に比例するのである。(中略) 体重が10倍になると、時間は1.8(101/4)倍になる」とのことだ。こうした生物の体重と時間(たとえば寿命)の関係は、べき乗則の一つといえる。
日本語や英語などを用いる自然言語モデルにも、こうしたべき乗則が存在する。「計算量」、「データ量」、「モデルの大きさ」が大きいほど、自然言語モデルの誤差は小さくなる、ということの発見である。それが、この論文のテーマとなっている。
論文では、3つのグラフが示されている。厳密な単位や尺度等を省略して、筆者がイメージ化して示すと、つぎのような感じになる。
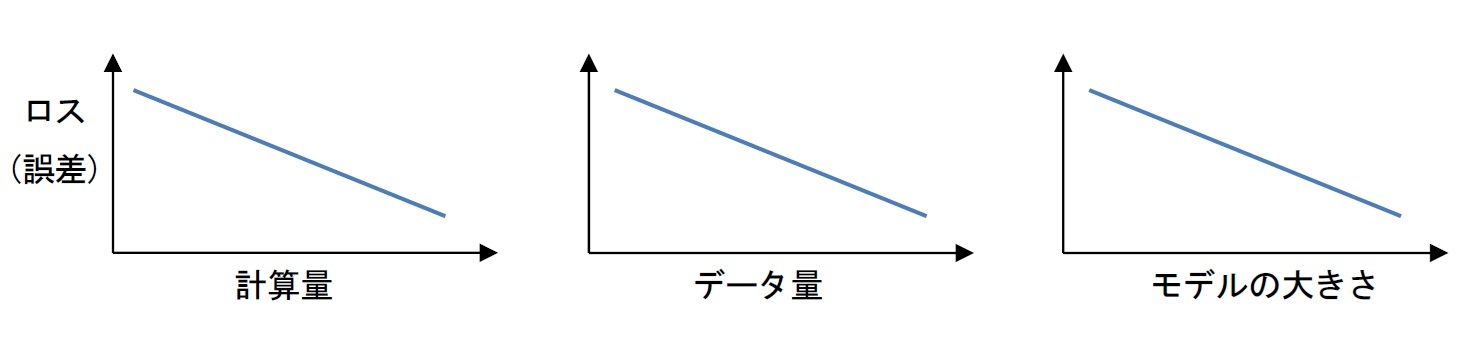
◇ 大きいモデルほど性能がよくなる、との結論は常識を覆すものとなった
データ量が大きいほど、モデルが改善されるというのも理解できる内容だ。ビッグデータなどの大量のデータを用いて学習するほど、誤差が減少するというのは、「まあそうだろう」との納得感がある。
問題は、モデルの大きさが大きくなるほど、モデルの性能が高まるという点だ。ここでいうモデルの性能というのは、会話のテーマを“予測”する性能だ。ディープラーニングの際に用いた学習データだけではなく、モデルが見たことのない未知データに対して行う予測の性能だ。
従来の考え方では、大きいモデル、つまり大量のパラメータを用いたモデルでは、未知データに対して行う予測の精度は下がってしまうとされてきた。この現象は、「過学習」と言われる。
これを人間の勉強に例えれば、試験前の丸暗記に相当する。数学の試験の前日に、問題を解くための定理や技法ではなく、試験範囲の問題と答えをひたすら丸暗記したとする。試験で、暗記したものとまったく同じものが出題されれば解答はできる。だが、数値や条件などを少し変えた問題が出題されたら、お手上げになってしまうだろう。つまり、未知の問題に対応するための応用力がないわけだ。
こうした過学習を避けるために、モデルの大きさは適切な規模にすべき、との考え方が従来は一般的であった。しかし、この論文は、こうした常識を覆すものとなった。(なお、このべき乗則の成立にはいくつかの条件が必要とされている。べき乗則は、AIの機械学習全般に当てはまるものではなく、トランスフォーマー構造といわれる言語モデルのディープラーニングを条件としている。)
この論文を裏付けとして、OpenAI社のChatGPT、Google社のBard (2024年2月にGeminiに改称)、Meta社のLLamaなど、大手IT企業による生成AIの開発競争が隆盛となっている。
◇ 生成AIはまだ改良の途上 ― さまざまな問題を抱えている
このうち、ハルシネーションとは、生成AIがユーザーの質問に対して、事実とは異なる回答を生成することを指す。その内容がもっともらしいために、ユーザーが回答の真偽を確かめにくい。このため、生成AIの回答を鵜呑みにすると、ユーザーや社会全体に誤解や混乱を巻き起こしてしまう恐れがあるとされる。
ハルシネーションが発生する原因として、学習データが古い情報であったり、偏った情報であったりすることや、学習プロセスに問題があったりすることが考えられる。ただ、その改善は簡単ではないとされる。
AIが人間社会で重要なツールとなっていくためには、予測や判断の性能を向上させるとともに、これらの問題への対応が欠かせない。
◇ 問題への対応のために “ラベラー” による修正が行われている
ここからは、筆者の想像する将来の話。多少、妄想も含まれているので、話半分で聞いていただきたい。
将来、ラベラーの役割を肩代わりする“ラベラーAI”が開発されるかもしれない。そうなれば、生成AIの改良に加速度がつくこととなろう。
生成AI(Generative Artificial Intelligence, GAI)の次に、間もなく登場するものとして、汎用AI(Artificial Gereral Intelligence, AGI)が注目されている。GAIの次に、AGIが登場するという流れだ。略語が似ていて、当初は少し戸惑うかもしれない。
汎用AIは、生成AIが進化したもので、さまざまな仕事(タスク)を人間と同等か、それ以上のレベルで実現できる-それが、汎用AIの特徴とされている。AIやロボット工学の専門家からは、汎用AIは、人々にとって、同僚や相談相手のような存在になるだろうと言われている。
ここまで考えると、ラベラーAIによる生成AIの応答の矯正は、どのように変化していくのかが気になってくる。やはり矯正は、引き続き人間が行うのか。だがそれでは、いつまでも人の手を離れないことになる。
それとも、「ラベラーAIによる生成AIの応答の矯正」を矯正する“ラベラー・ラベラーAI”が開発されるのか。そうなると、ラベラー・ラベラーAIの応答の矯正は、一体誰が行うのか...。
このようなとりとめもないことを考えつつ、生成AIの開発や進化に関する日々のニュースを見ていくのも、なかなか面白いと思われるが、いかがだろうか。
(参考文献)
“Scaling Laws for Neural Language Models” Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei (arXiv:2001.08361 [cs.LG], https://doi.org/10.48550/arXiv.2001.08361)
「ゾウの時間・ネズミの時間」(本川達雄著, 中公新書, 1992年)
「大規模言語モデルは新たな知能か-ChatGPTが変えた世界」(岡野原大輔著, 岩波科学ライブラリー 319, 岩波書店, 2023年)
「平成28年 情報通信白書」(総務省)
「大規模言語モデル」「ChatGPT」「ハルシネーション」(ナレッジインサイト 用語解説, 野村総合研究所サイト)
(2024年06月18日「研究員の眼」)
このレポートの関連カテゴリ

 各種レポート配信をメールでお知らせ。読み逃しを防ぎます!
各種レポート配信をメールでお知らせ。読み逃しを防ぎます!
保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員
篠原 拓也 (しのはら たくや)
研究・専門分野
保険商品・計理、共済計理人・コンサルティング業務
03-3512-1823
- 【職歴】
1992年 日本生命保険相互会社入社
2014年 ニッセイ基礎研究所へ
【加入団体等】
・日本アクチュアリー会 正会員
篠原 拓也のレポート
| 日付 | タイトル | 執筆者 | 媒体 |
|---|---|---|---|
| 2025/05/27 | 気候指数 2024年データへの更新-日本の気候の極端さは1971年以降の最高水準を大幅に更新 | 篠原 拓也 | 基礎研レポート |
| 2025/05/20 | 「次元の呪い」への対処-モデルの精度を上げるにはどうしたらよいか? | 篠原 拓也 | 研究員の眼 |
| 2025/05/13 | チェス盤を用いた伝心-愛情と計算力があれば心は通じる? | 篠原 拓也 | 研究員の眼 |
| 2025/05/09 | 国民負担率 24年度45.8%の見込み-高齢化を背景に、欧州諸国との差は徐々に縮小 | 篠原 拓也 | 基礎研マンスリー |






新着記事
-
2025年10月16日
EIOPAが2026年のワークプログラムと戦略的監督上の優先事項を公表-テーマ毎の活動計画等が明らかに- -
2025年10月16日
再び不安定化し始めた米中摩擦-経緯の振り返りと今後想定されるシナリオ -
2025年10月15日
インド消費者物価(25年10月)~9月のCPI上昇率は1.5%に低下、8年ぶりの低水準に -
2025年10月15日
「生活の質」と住宅価格の関係~教育サービス・治安・医療サービスが新築マンション価格に及ぼす影響~ -
2025年10月15日
IMF世界経済見通し-世界成長率見通しは3.2%まで上方修正
レポート紹介
-
研究領域
-
経済
-
金融・為替
-
資産運用・資産形成
-
年金
-
社会保障制度
-
保険
-
不動産
-
経営・ビジネス
-
暮らし
-
ジェロントロジー(高齢社会総合研究)
-
医療・介護・健康・ヘルスケア
-
政策提言
-
-
注目テーマ・キーワード
-
統計・指標・重要イベント
-
媒体
- アクセスランキング
お知らせ
-
2025年07月01日
News Release
-
2025年06月06日
News Release
-
2025年04月02日
News Release
【大規模言語モデルの裏付け理論-大きいモデルほど高性能!?】【シンクタンク】ニッセイ基礎研究所は、保険・年金・社会保障、経済・金融・不動産、暮らし・高齢社会、経営・ビジネスなどの各専門領域の研究員を抱え、様々な情報提供を行っています。
大規模言語モデルの裏付け理論-大きいモデルほど高性能!?のレポート Topへ- 新型コロナウイルス
- ウィズコロナ・アフターコロナ
- 生成AI・AI
- IoT
- デジタルトランスフォーメーション(DX)
- フィンテック(FinTech)
- キャッシュレス
- デジタル通貨
- デジタルプラットフォーム
- マイナンバー
- MaaS、CASE
- SDGs
- ESG
- 気候変動
- カーボンニュートラル・脱炭素社会
- サステナビリティ
- ウェルビーイング
- 生物多様性
- イデコ(iDeCo)
- 新NISA・NISA
- 日本銀行
- 人手不足・人材不足
- 働き方改革
- 人的資本経営
- 従業員エンゲージメント
- テレワーク・在宅勤務
- ダイバーシティ(多様性)社会
- 外国人雇用・就労
- 労働政策
- 地域包括ケア・地域共生社会
- 認知症
- 金融(ファイナンシャル)ジェロントロジー
- 全世代型社会保障
- 社会保障・税改革
- 医療・介護制度改革
- 健康寿命
- 健康経営
- 格差・貧困
- 世代間格差
- パワーカップル
- 未婚化
- プレコンセプションケア
- 少子高齢化
- 東京一極集中
- インバウンド
- シェアリングエコノミー
- Z世代・α世代
- エンタメ
- オフィスレントインデックス
- 生命保険事業概況
- 米中貿易摩擦
- 米国
- 中国
- 欧州
- アジア・新興国
- 韓国
- ASEAN
- 統計
- 確定拠出年金
- 企業型DC
- 資産所得倍増プラン
- 金融リテラシー
- 住宅リテラシー
- 年金制度改革
- インド
- 経済安全保障
- 供給網(サプライ・チェーン)
- 消費者物価指数(CPI)│日本
- 雇用統計│日本
- 鉱工業生産指数│日本
- 貿易統計│日本
- 法人企業統計│日本
- QE速報・予測
- 日銀金融政策決定会合
- 日銀短観│日本
- 資金循環統計│日本
- 景気ウォッチャー調査│日本
- 地域経済報告(さくらレポート)
- マネタリーベース│日本
- GDP等│米国
- FOMC(連邦公開市場委員会)│米国
- 住宅販売・着工│米国
- 雇用統計│米国
- 米個人所得・支出|米国
- ECB政策理事会│欧州
- ユーロ圏消費者物価指数
- ユーロ圏GDP
- ユーロ圏失業率
- 英国雇用関連統計
- 英国金融政策
- 英国GDP
- 将来人口推計
- 人口動態統計
- 宿泊旅行統計
- 中国GDP
- インドGDP
- タイGDP
- マレーシアGDP
- フィリピンGDP
- インドネシアGDP
- ベトナムGDP
- ロシアGDP
- ブラジルGDP
- IMF世界経済見通し
- 企業物価指数
- インド消費者物価
Copyright © NLI Research Institute. All rights reserved.