










- シンクタンクならニッセイ基礎研究所 >
- 保険 >
- 保険計理 >
- 「次元の呪い」への対処-モデルの精度を上げるにはどうしたらよいか?
「次元の呪い」への対処-モデルの精度を上げるにはどうしたらよいか?

保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員 篠原 拓也
このレポートの関連カテゴリ


文字サイズ
- 小
- 中
- 大
今世紀初頭から、IT化の進展を背景に世界的にその概念が徐々に広がっていった。日本では、この言葉は2010年頃から一般に使われ始めた。2013年には、新語・流行語大賞の候補として選ばれたが、大賞には選ばれなかった。それから10数年が経過するなかで、DX(デジタルトランスフォーメーション)、AI(人工知能)、生成AIなど、ビッグデータをベースとした展開が次々にあらわれてきた。
ビッグデータについては、「次元の呪い」と言われるデータの複雑さゆえの問題が、当初から指摘されてきた。この問題にはどのような取り組みがなされているのか。本稿では、この点を中心に見ていくこととしたい。
◇ 「次元の呪い」とは
アメリカで制御理論等の応用数学者であったリチャード・ベルマン博士によって生み出された。例として、1メートルの空間を隣接する点が1センチ幅となるよう、格子点で埋めようとすると、1次元(直線)ならば100個の点で足りる。2次元(平面)だと1万個(=100の2乗個)、3次元(立体)だと100万個(=100の3乗個)の格子点が必要となる。(視覚的に捉えるのは困難だが頭の中でイメージするとして)10次元(超立体)では、1垓(がい)個(=100の10乗個)もの格子点が必要となる。
このように、次元が増すごとに、空間を埋める格子点の数は指数関数的に増えていく。
◇ 「次元の呪い」がもたらす問題
(1) 複数の色付き電球が作り出す状態の解明
例えば、0と1でオフとオンを表す、異なる色付きの電球が複数個ある場合を考える。電球の数がr個のときに、それらがオフまたはオンになることで、重なり合ってできる色の種類は2のr乗個となる。ここで、このようにして重なり合った色の状態が1つ与えられたとしよう。どの電球がオフでどの電球がオンとなってその状態が生じているのかを明らかにしようとすると、2のr乗個の状態それぞれについて確認が必要となる。rの数が増えれば、確認のための手間は膨大となる。
(2) 複数の食材から作ることのできる料理の検討
冷蔵庫の中にいくつかの食材があったとしよう。それらを使って、夕食をつくることにした。食材が5つであれば、つくることのできる料理の数は限られるため、それほど悩むことなく料理を決めてその準備に取りかかることができる。しかし、食材が100種類もあると、さまざまな料理が可能となり、どの料理をつくろうか、下味はどうするか、出汁は何でとるか等々、料理を決める段階で大いに迷ってしまう可能性がある。
(3) お店で買うシャツを選ぶ場合の検討
アパレルショップでシャツを買う場合について考える。「明るい色のシャツでカジュアルとして着られるもの」という程度の条件で選んでいけば、いくつか見たり試着したりして買うシャツを決められるだろう。しかし、色は白かピンクか水色、デザインは無地かストライプかチェック、素材はコットンかポリエステルかリネン、用途はカジュアルかアウトドアかスポーツ、値段は安いものか中価格帯かセール、などと条件を設定すると、これらの条件を満たすものは243通り(=3の5乗)にもなる。選択肢が増え過ぎてしまい、買うシャツがなかなか見つけられなくなる。
◇ 「次元の呪い」が機械学習にもたらす弊害
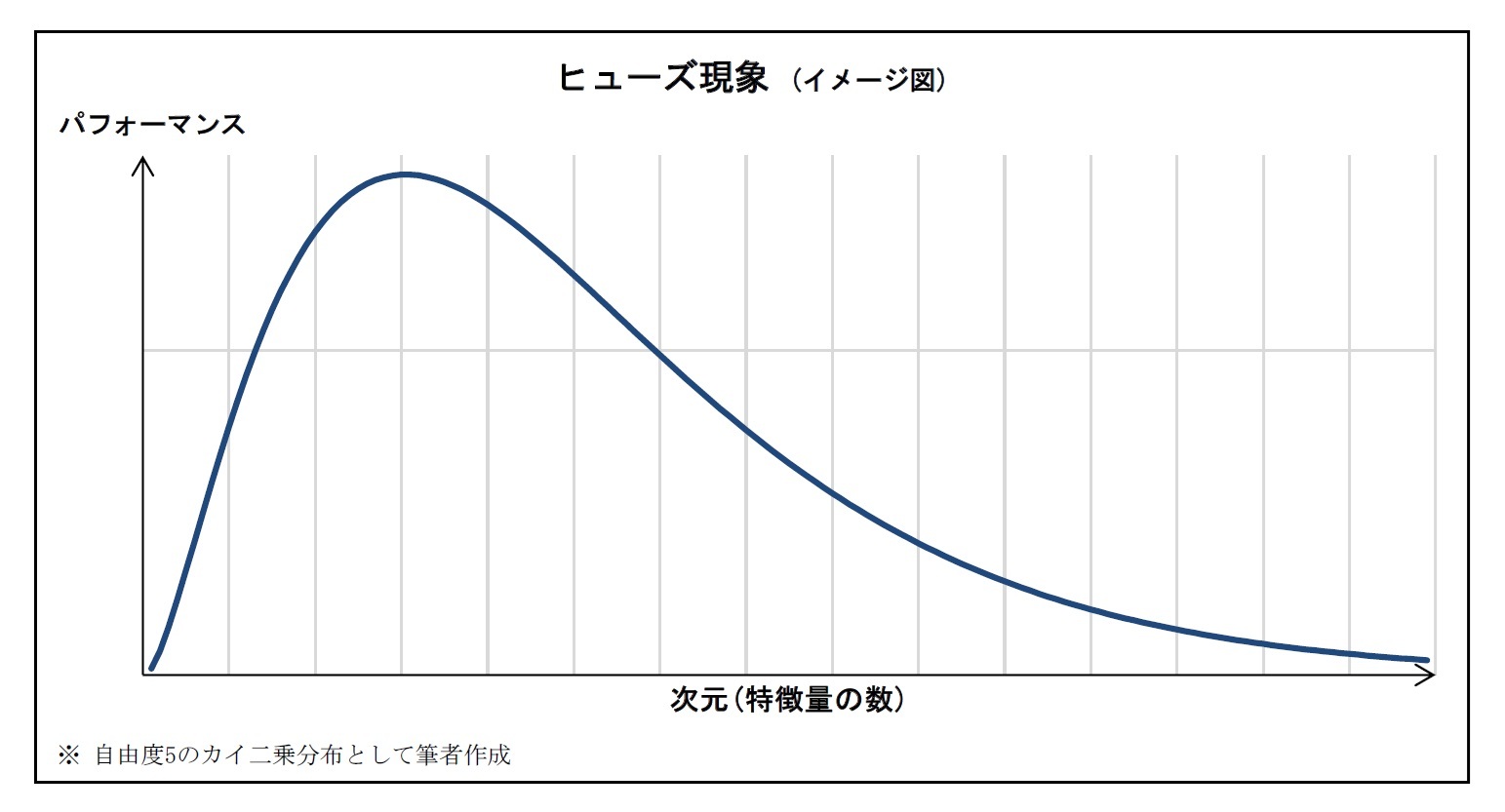
〈1〉学習データの不足
次元を増やすと、取りうる状態の数は指数関数的に増える。その結果、ほとんどの状態に対する学習データが存在せず、機械学習が困難となる。
〈2〉計算の増加
次元を増やすと、データを処理するための計算量と時間が増える。このため、機械学習の負荷が大きくなる。
〈3〉過学習
次元を増やすと予測や分類のためのモデルが過度に複雑となる。その結果、モデルが、データに潜むパターンではなくノイズに適合してしまう可能性がある。これにより、新しいデータをもとに予測や分類を行ったときに、モデルの能力が低下してしまう。
〈4〉誤差距離の意義の薄弱化
機械学習においては、実際の値とモデルの出力の差を誤差として扱い、これを小さくするとことでモデルの精度を向上させていく。しかし、高次元空間では、2つのデータポイント間の距離が極端に大きくなることがあり、誤差の距離が意義が薄れてしまうことがある。
◇ 「次元の呪い」への対処
〔1〕主成分分析(Principal Component Analysis, PCA)
主成分分析は、元の変数を、元の変数の線形結合である新しい変数に変換する統計手法だ。この新しい変数は、主成分と呼ばれる。主成分分析により、主成分に置き換えて、残りの次元を減らすことで、データを簡明に分析することができる。
〔2〕線形判別分析(Linear Discriminant Analysis, LDA)
データの差異が大きい特徴量を統計的に特定する手法だ。特に、分類を行うモデルで有用となる。線形判別分析によって特定された特徴量の線形結合により新たな変数を作成することで、精度の高い分類モデルを作ることができる。
〔3〕t-分布型確率的近傍埋め込み(t-distributed Stochastic Neighbor Embedding, t-SNE)
低次元での距離の分布を、正規分布ではなく、裾野の厚いt-分布に従うものと仮定する。そのうえで、データがまばらで距離が大きくなりがちな高次元での距離分布が低次元にも合致するよう、データの変換を行う。条件付確率を用いて類似度を表すことで、高次元でのデータの局所的な構造を低次元でも維持する(類似しているデータを低次元上でも近くに保つ)ことを可能としている。
〔4〕自己符号化器(オートエンコーダー) (Autoencoder)
次元の削減や有効な次元の抽出を、ニューラルネットワークを用いて行う方法だ。入力されたデータを一度圧縮し、重要な特徴量だけを残した後、再度もとの次元に復元処理をするアルゴリズムを意味する。特に、画像認識などの分野で威力を発揮するとされる。
PCAやLDAは、新たな変数の作成を線形に行う線型手法とされる。複雑なデータでは、予測や分類の一定の精度低下が避けられない場合がある。
一方、t-SNEや自己符号化器は、非線形手法と位置づけられる。t-SNEは、計算負荷が大きく、大規模データセットでの適用が難しい場合がある。また、自己符号化器は復元処理の誤差が大きくなり、分類の精度が低下する場合がある。
◇ AI開発の動向からは目が離せない
実は、最新のAIのニューラルネットワークモデルでは、予測や分類の誤差の評価に、距離による測定を用いないものが多くなっているといわれる。それによって次元の呪いから逃れることができるという。ただし、それに伴って別の問題が生じる可能性は無視できないかもしれない。
例えば、そうした距離を用いない評価が人間の肌感覚に合うものかどうか。また、そもそも人間のアナログな肌感覚など最初から考慮せずに、結果のパフォーマンスのみを追求することとなるのか…。
AI開発は日進月歩の状況が続く。その動向について、引き続き注視していくこととしたい。
(参考資料)
“The Curse of Dimensionality in Machine Learning: Challenges, Impacts, and Solutions” Abid Ali Awan (datacamp / WRITE FOR US, Sep 13, 2023)
“Curse of Dimensionality in Machine Learning”(Geeks for Geeks, Last Updated: 11 Dec, 2024)
“What Is the Curse of Dimensionality?” Badreesh Shetty(Updated by Jessica Powers)(Built in, Aug 19, 2022)
“Curse of Dimensionality”(Wikipedia)
(2025年05月20日「研究員の眼」)
このレポートの関連カテゴリ

 各種レポート配信をメールでお知らせ。読み逃しを防ぎます!
各種レポート配信をメールでお知らせ。読み逃しを防ぎます!
保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員
篠原 拓也 (しのはら たくや)
研究・専門分野
保険商品・計理、共済計理人・コンサルティング業務
03-3512-1823
- 【職歴】
1992年 日本生命保険相互会社入社
2014年 ニッセイ基礎研究所へ
【加入団体等】
・日本アクチュアリー会 正会員
篠原 拓也のレポート
| 日付 | タイトル | 執筆者 | 媒体 |
|---|---|---|---|
| 2025/05/27 | 気候指数 2024年データへの更新-日本の気候の極端さは1971年以降の最高水準を大幅に更新 | 篠原 拓也 | 基礎研レポート |
| 2025/05/20 | 「次元の呪い」への対処-モデルの精度を上げるにはどうしたらよいか? | 篠原 拓也 | 研究員の眼 |
| 2025/05/13 | チェス盤を用いた伝心-愛情と計算力があれば心は通じる? | 篠原 拓也 | 研究員の眼 |
| 2025/05/09 | 国民負担率 24年度45.8%の見込み-高齢化を背景に、欧州諸国との差は徐々に縮小 | 篠原 拓也 | 基礎研マンスリー |






新着記事
-
2025年10月14日
今週のレポート・コラムまとめ【10/7-10/10発行分】 -
2025年10月10日
企業物価指数2025年9月~国内企業物価の上昇率は前年比2.7%、先行きは鈍化予想~ -
2025年10月10日
中期経済見通し(2025~2035年度) -
2025年10月10日
保険・年金関係の税制改正要望(2026)の動き-関係する業界・省庁の改正要望事項など -
2025年10月10日
若者消費の現在地(4)推し活が映し出す、複層的な消費の姿~データで読み解く20代の消費行動
レポート紹介
-
研究領域
-
経済
-
金融・為替
-
資産運用・資産形成
-
年金
-
社会保障制度
-
保険
-
不動産
-
経営・ビジネス
-
暮らし
-
ジェロントロジー(高齢社会総合研究)
-
医療・介護・健康・ヘルスケア
-
政策提言
-
-
注目テーマ・キーワード
-
統計・指標・重要イベント
-
媒体
- アクセスランキング
お知らせ
-
2025年07月01日
News Release
-
2025年06月06日
News Release
-
2025年04月02日
News Release
【「次元の呪い」への対処-モデルの精度を上げるにはどうしたらよいか?】【シンクタンク】ニッセイ基礎研究所は、保険・年金・社会保障、経済・金融・不動産、暮らし・高齢社会、経営・ビジネスなどの各専門領域の研究員を抱え、様々な情報提供を行っています。
「次元の呪い」への対処-モデルの精度を上げるにはどうしたらよいか?のレポート Topへ- 新型コロナウイルス
- ウィズコロナ・アフターコロナ
- 生成AI・AI
- IoT
- デジタルトランスフォーメーション(DX)
- フィンテック(FinTech)
- キャッシュレス
- デジタル通貨
- デジタルプラットフォーム
- マイナンバー
- MaaS、CASE
- SDGs
- ESG
- 気候変動
- カーボンニュートラル・脱炭素社会
- サステナビリティ
- ウェルビーイング
- 生物多様性
- イデコ(iDeCo)
- 新NISA・NISA
- 日本銀行
- 人手不足・人材不足
- 働き方改革
- 人的資本経営
- 従業員エンゲージメント
- テレワーク・在宅勤務
- ダイバーシティ(多様性)社会
- 外国人雇用・就労
- 労働政策
- 地域包括ケア・地域共生社会
- 認知症
- 金融(ファイナンシャル)ジェロントロジー
- 全世代型社会保障
- 社会保障・税改革
- 医療・介護制度改革
- 健康寿命
- 健康経営
- 格差・貧困
- 世代間格差
- パワーカップル
- 未婚化
- プレコンセプションケア
- 少子高齢化
- 東京一極集中
- インバウンド
- シェアリングエコノミー
- Z世代・α世代
- エンタメ
- オフィスレントインデックス
- 生命保険事業概況
- 米中貿易摩擦
- 米国
- 中国
- 欧州
- アジア・新興国
- 韓国
- ASEAN
- 統計
- 確定拠出年金
- 企業型DC
- 資産所得倍増プラン
- 金融リテラシー
- 住宅リテラシー
- 年金制度改革
- インド
- 経済安全保障
- 供給網(サプライ・チェーン)
- 消費者物価指数(CPI)│日本
- 雇用統計│日本
- 鉱工業生産指数│日本
- 貿易統計│日本
- 法人企業統計│日本
- QE速報・予測
- 日銀金融政策決定会合
- 日銀短観│日本
- 資金循環統計│日本
- 景気ウォッチャー調査│日本
- 地域経済報告(さくらレポート)
- マネタリーベース│日本
- GDP等│米国
- FOMC(連邦公開市場委員会)│米国
- 住宅販売・着工│米国
- 雇用統計│米国
- 米個人所得・支出|米国
- ECB政策理事会│欧州
- ユーロ圏消費者物価指数
- ユーロ圏GDP
- ユーロ圏失業率
- 英国雇用関連統計
- 英国金融政策
- 英国GDP
- 将来人口推計
- 人口動態統計
- 宿泊旅行統計
- 中国GDP
- インドGDP
- タイGDP
- マレーシアGDP
- フィリピンGDP
- インドネシアGDP
- ベトナムGDP
- ロシアGDP
- ブラジルGDP
- IMF世界経済見通し
- 企業物価指数
- インド消費者物価
Copyright © NLI Research Institute. All rights reserved.