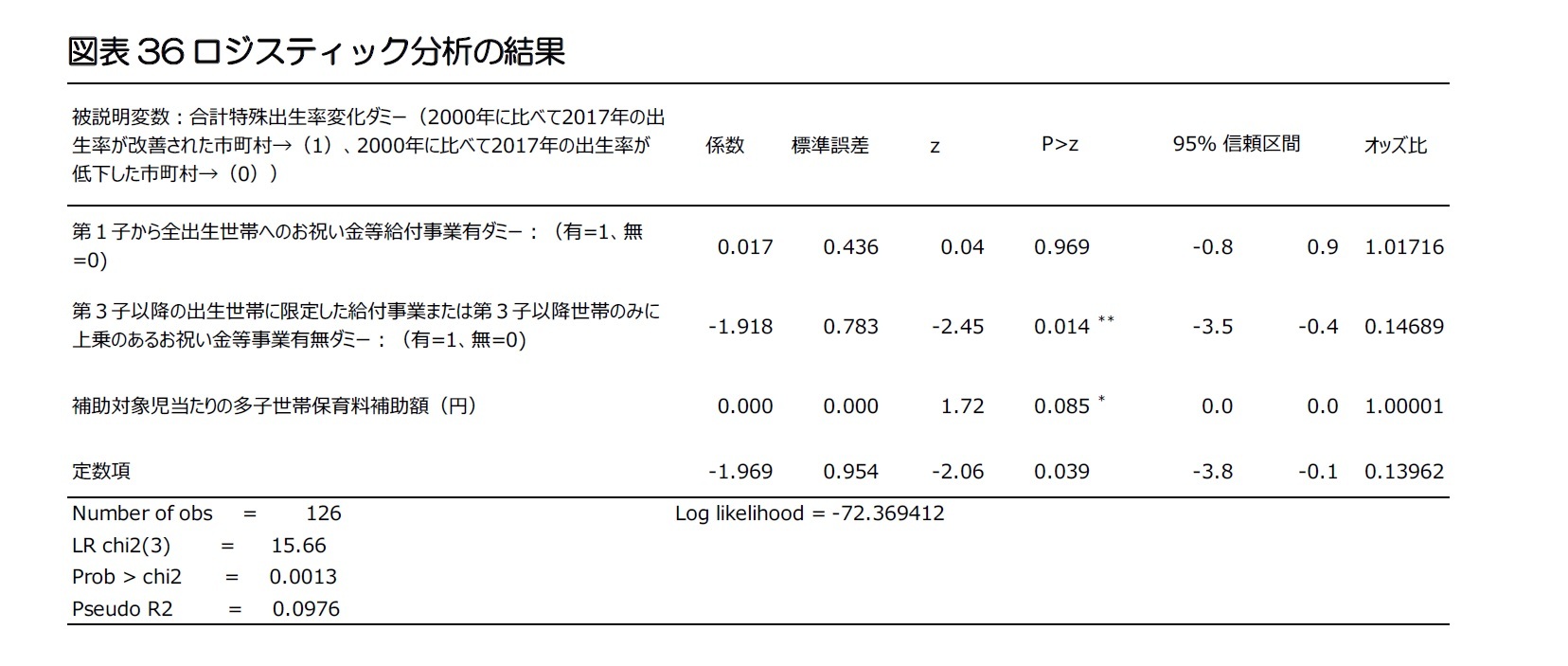
(4)ロジスティック分析
被説明変数が量的データである一般的な回帰分析は、説明変数と被説明変数の間の線形関係を仮定しており、一般線形モデル(Ordinary Linear Model)と呼ばれている。しかしながら社会のすべての現象が線形的な関係ではないので、非線形的な関係に対する分析も必要である。また、現実的には被説明変数が量的(Quantitative)データではなく質的(Qualitative)データであるケースも多い。例えば、所得がいくらぐらいである時、家を所有するか、給料がどのぐらいある時、車を買うか、年収がどのぐらいである時、結婚するかなど説明変数は量的データあるものの、被説明変数は「家を所有している、家を所有していない」のような質的データになっている場合がある4。
このように被説明変数が質的データであっても分析ができるよう一般線形モデルを拡張したのが一般化線形モデル(GLM:Generalized Linear Model)である。一般線形モデルが、被説明変数が正規分布をしている時のみを扱っていることに比べて、一般化線形モデルは、正規分布以外の分布(二項分布、ポアソン分布等)に従う被説明変数を予測する時にも使われる。また、一般線形モデルでは被説明変数と説明変数の線形的な関係を推計することに対して、一般化線形モデルは2値変数を扱えるようにするために被説明変数を適切な関数に変えたf(x)と説明変数の関係を推計する。このような一般化線形モデルで最も使われている分析方法がロジスティック分析である。
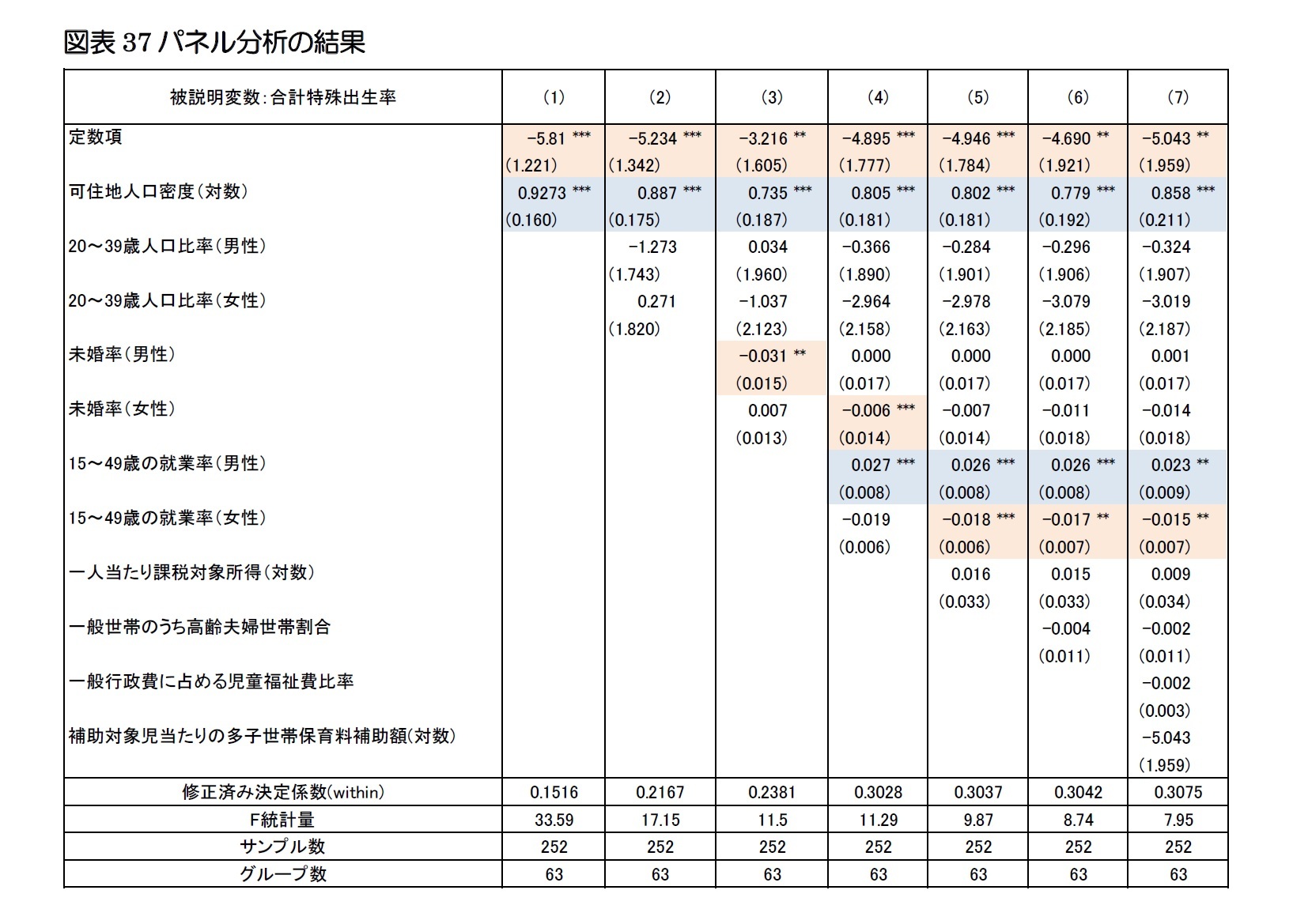
(5)パネル分析
パネルデータ5を通常の最小二乗法で推定した場合、推定値にバイアスが発生する恐れがある。つまり、通常の最小二乗法では企業や個人の持っている固有効果を誤差項に含めて推定を行っているが、その結果、固有効果により誤差項に自己相関が発生したり、誤差項が説明変数と相関するために、BLUE(Best Linear Unbiased Estimator、最良線形不偏推定量)を得るための誤差項の仮定が満たされなくなるケースが多い。そこで、パネル分析を行った6。
Juan M. Villa "Diff: simplifying the causal inference analysis with difference-in-differences" 18th London Stata Users Group Meeting September 12th, 2012
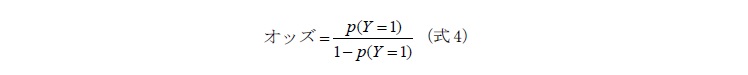{kind=link}
{kind=link}
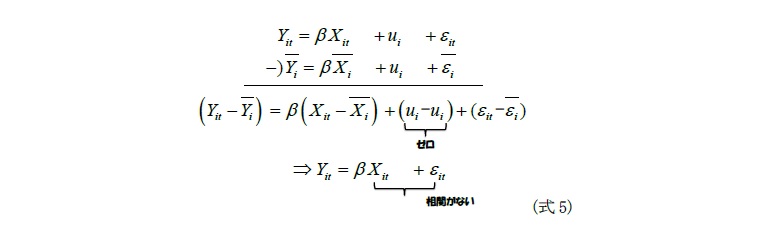{kind=link}
{kind=link}