{kind=link}
{kind=link}
保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員
篠原 拓也(しのはら たくや)
研究領域:保険
研究・専門分野
保険商品・計理、共済計理人・コンサルティング業務
関連カテゴリ
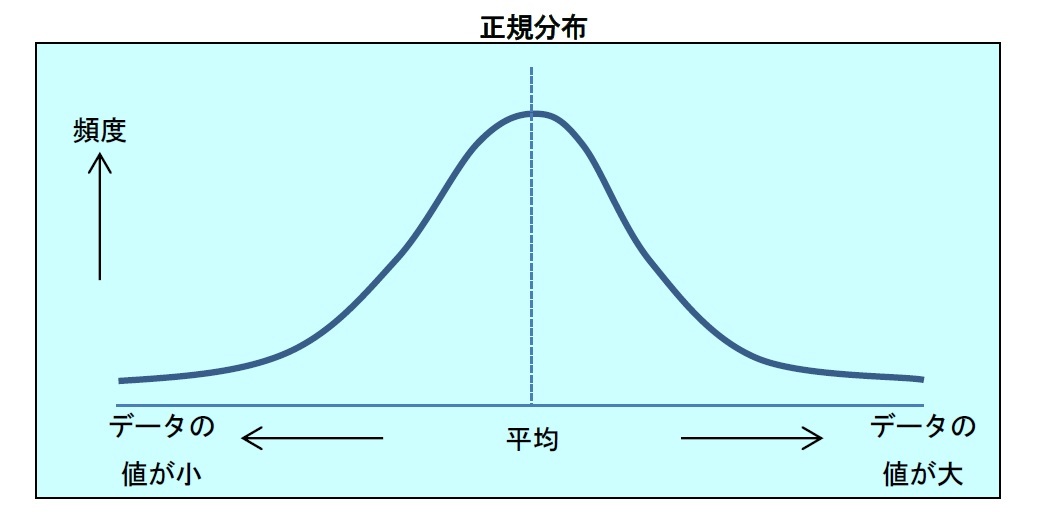
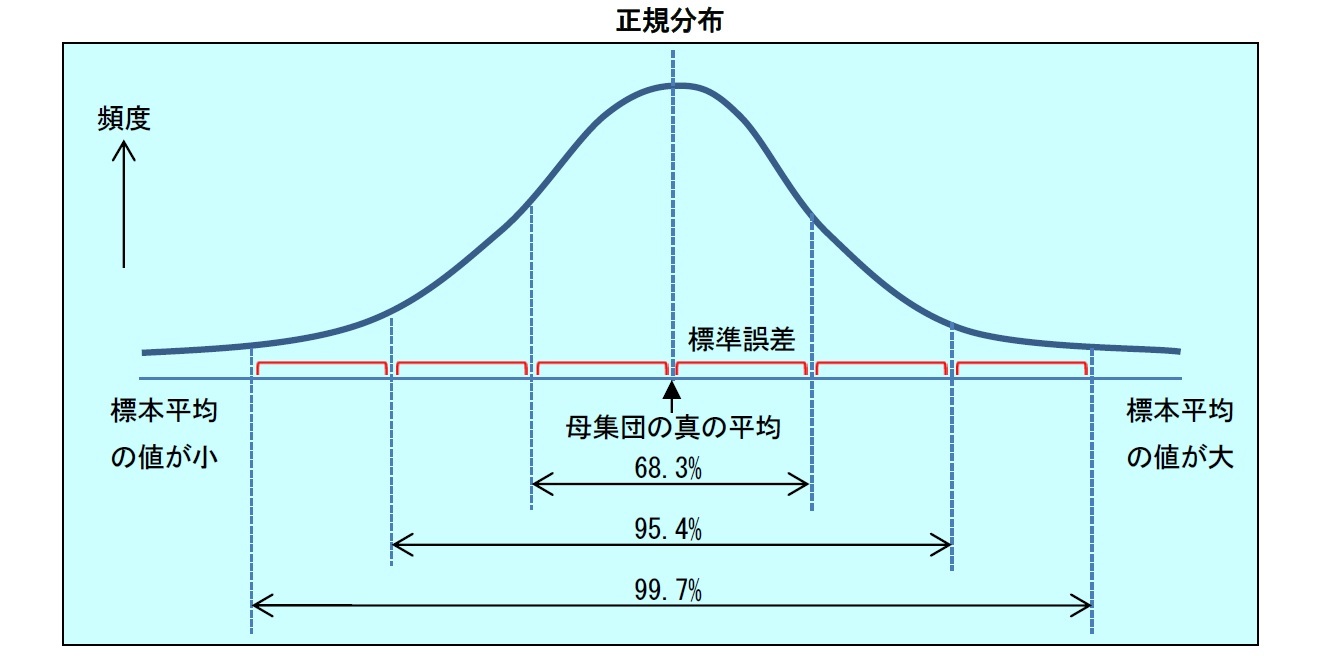
分散が存在するようなデータの母集団を考える。この母集団から、標本データをいくつか取り出して、その平均を計算してみよう。この標本データの平均のことを、「標本平均」と呼ぶ。取り出す標本データの数を、どんどん増やしていくと、標本平均はどうなるだろうか。
実は、データの母集団が、二項分布や、ポアソン分布など、どのような分布であったとしても、標本平均は、母集団の真の平均を中心とした、正規分布に、近似的に従うことになる。
保険研究部 主席研究員 兼 気候変動リサーチセンター チーフ気候変動アナリスト 兼 ヘルスケアリサーチセンター 主席研究員
研究領域:保険
研究・専門分野
保険商品・計理、共済計理人・コンサルティング業務
【職歴】
1992年 日本生命保険相互会社入社
2014年 ニッセイ基礎研究所へ
【加入団体等】
・日本アクチュアリー会 正会員